


Since 1987, I've used almost every available technology to transfer data across disparate infrastructures, including punch cards, platters, tape, floppy devices, portable block storage cartridges and USB devices. Each required some form of data encapsulation into a payload or packet to be sent to a destination, where it was received and presented to the I/O subsystem for processing. The challenge was always understanding the payload's contents, format, and destination. Different ways to replicate data
The transmission of the data can be broken into three simple categories. File Level, Byte Level or Block Level replication. The simplest explanation of the differences is:
- File Level - Copies all its information at the application level using standard functions of the Operating System.
- Byte Level - Copies all changed information at the byte level through File System I/O defined to that Operating System
- Block Level – Copies changed disk blocks at the hardware level using Change Block Tracking and specific device drivers.
File level replication is often deployed for small scale, non-system state, static data movement. It can be used in conjunction with disaster recovery (DR), or large migration projects but, since file level replication places exclusive locks on the files and folders or requires a dedicated system, it is not an ideal option for the replication needs for these types of projects. Therefore, it will not be included in this article.
I have often been asked about the differences between Block and Byte Level replication. People see the end results as “the same” and do not understand what the big deal is between one or the other.
The difference is like using an 18-wheeler to deliver a single pizza to the next block, versus using a bicycle to haul the contents of an entire supermarket across the city. Yes, it can be done, but the efficiency is questionable.
Understanding the systems and how they are organized
When moving server information, whether the entire system state or just application data, it's crucial to understand the systems. Systems are organized into layers to provide a standardized framework that allows for flexibility and change. Applications work with operating systems, which define the frameworks used by hardware to communicate. The operating system controls the information passed between the application layer and the hardware layer. This layering allows new technologies to be rapidly deployed with backward compatibility, enabling different layers to gradually adapt to the new technology.

When creating functions that are specific to any layer, the benefits and limitations must be weighed to accomplish overall value to the users.
- System State Replication tools for Windows and Linux are generally based on sectors and blocks of the hardware layer or on File I/O of the Operating System layers.
- Application Layer Replication tools are limited to the applications and are independent of the OS or Hardware and are not part of this discussion around Block vs Byte Level replication.
- Byte Level Replication works through the OS layer using the [local] File system, so it is abstracted from the hardware. As the application writes data to disk, the File System sends the I/O to the hardware to process it accordingly for that specific hardware.
- Block Level Replication usually works closer to the Hardware layer using a point-in-time (PIT) image of the disk. This is done using block level changes through a Change Block Tracking (CBT) process that is also known as Resilience Change Tracking, dirty bit maps, Dirty Disk Cache, VHD Difference disk and other various names.
Disk sectors and blocks
Before we go much further, we need to have a basic understanding of disk sectors (or disk pages) and blocks. This concept is fundamentally the same whether you are using HDD, SSD, NVMe, SCSI and even USB.
- Disk sector sizes are defined by the OS and can vary between systems. The most common sector size is 512 bytes, but some storage arrays default to 4096 bytes (4k) sectors. Most SSD and NVMe pages are 4k.
- Disk blocks are also defined by the OS and can also vary between systems. The most common size of a disk block is 8 sectors or 4k.
- File I/O is defined by the chosen file system running on the OS. Most OS’s support several different file system types. This comparison is based on Windows NTFS and Linux EXTn type file systems. File I/O sizes are variable with a maximum size, in most cases, of the Block size defined to the hardware.
Sectors, Blocks, and file I/O all require header and, often, footer information within the ‘payload’ of data. The header/footer sizes vary based on several factors, including OS and manufacturer settings. Storage devices often provide “format efficiency” indicators to show how much is actual data vs how much is header or footer.
As File I/O is written to the disk, it is processed in disk Sectors and Blocks. This article is not about writing to disk but sending information across a TCP/IP connection to a different system to be processed. Basic understanding of the TCP/IP process helps with this concept:
The replicated data is eventually sent to TCP/IP which has a maximum header/footer size of 15 words (32bit word size) which is 60 bytes ((32 divided by 8) times 15).
Ethernet communications have a Maximum Transmission Unit (MTU) of 1,500 bytes. For optimal transmission performance, ensure your header, footer, and payload together total 1,500 bytes or a multiple of it.
To be clear, there are many factors involved with TCP/IP performance that are not included in the discussion. This is not intended to be a TCP/IP performance discussion.
Block level and byte level replication processes
Armed with the basic understanding of Layers, Sectors, Blocks, File I/O, headers, payloads and transmission sizes defined above we can now talk about the Processes.
- Block Level Replication
For block level replication, essentially, every time a block of data is changed, it gets flagged in the Change Block Tracking (CBT) table. Then, at a user-configured interval, often between 15 minutes and 1 hour, the block level replication process will copy those changed blocks to the destination, overwriting anything that already exists at the destination.
- Byte Level Replication
In byte-level replication, the File System (such as NTFS or EXTn) formats the information with a header, payload, and footer. The File System then hands off the I/O to the hardware driver, which writes the sectors and flags the CBT blocks. Once the information is successfully written to the disk, byte-level replication sends a copy of the I/O to the TCP/IP presentation layer, usually within sub-milliseconds.
I have provided a high-level overview of the process for block and byte level transmission:
When an application makes a change, the Application Layer passes the request to the Operating System, which formats the request based on the File System. It then sends that File I/O request to the Hardware Layer, as shown in the diagram below as item 1 in yellow. The sector containing the changed data is updated accordingly and written to the disk as shown in light blue items 1, 2 and 3.
For block level replication, this change kicks off a CBT table update indicating which block is different since it was last synchronized to the target as shown in purple items 1.
At a pre-determined time (usually 15 min or more), a process is executed that collects the changes in the CBT table and writes them to the TCP/IP presentation layer to be sent to the destination (target) as shown in the purple items 2 and 3.
For byte level File I/O replication, the I/O is copied and sent directly to the TCP/IP Presentation Layer from the OS Layer as soon as the original disk write is successful, as shown in the green arrow labeled item 1 in the diagram.
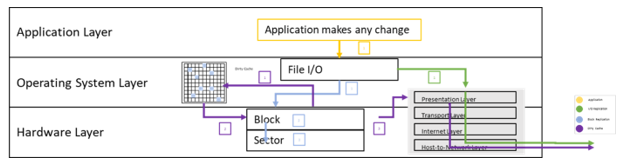
In a very simplified example:
If you create an empty .txt document and place the character “A” in it, then save it to disk, the file size is reported as 1 byte. The creation of the file and addition of the “A” requires their own I/O that both block and byte level replication addresses; however, a write of 1 block of data containing 8 sectors totaling 4,096 bytes will need to be performed to the disk.
Modern technologies, cache optimization, parsing and compression of information optimizes that process significantly, but nonetheless, 1 block is changed.
For replication based on disk sectors and blocks, the CBT table is flagged that a block of data has been changed and needs to be synchronized.
Again, modern techniques may improve the total amount of data moved around for block level replication, but it requires a little effort.
Once the processing for the ‘dirty blocks’ are completed they are handed to TCP/IP to process again into a maximum of 1,500 bytes, including header and footer.
When considering the same actions using an agent-based byte level replication tool, the I/O was copied into a memory queue, with no additional disk activity. Once successfully written to disk, an acknowledgement is returned from the hardware layer to the application layer. The acknowledgement initiates the copy of the I/O to be sent to the TCP/IP presentation layer for processing, without the need for any additional activities, processing, or requests.
The creation of the file consumes its own File I/O actions. The addition of the letter “A” and save of the file creates their set of File I/O. Any I/O that requests a change to the disk (Insert/Update/Delete) has the I/O copied and sent to the target where the agent on the target receives the I/O and processes it through the File System with write-order fidelity.
Multiple block change requests to different blocks of data at 4,096 bytes per block, even when they are cached, would consume more source resources than the byte level changes processed by byte level replication. At minimum, a single block change from disk to the switch transport layer for TCP/IP will require 3 TCP/IP requests.
Block level processing
As stated previously, a disk block is just over 4k bytes, but a TCP/IP Packet is about 1.5k bytes. So, every block sent can potentially take up more than 2.5 IP transactions. Advanced logic and processes can compress that block of data and package it into a set of full IP packets, but that is additional resource consumption that results in extra overhead and additional, often unplanned for, impact and costs.
The impact on the network is usually significant enough to require a dedicated route to the destination so as not to adversely affect production network use.
If there is any network disconnect, block level replication would need to restart from the beginning to ensure the destination is accurate. At cutover, a final synch is required to push the last changes to the target. This final synch has a variable time since many of the environments will flush cached information to temporary files on disk, which get cleared or deleted at startup so, are essentially extraneous overhead that can’t be avoided.
Byte level processing
The file system I/O packet contains a header, payload and may require a footer. The header contains information about the payload (the operation, file information, owner, structure and other metadata). The payload is as big as it needs to be, if a footer is required, it usually contains hash info about the payload and other validation items to ensure the complete packet is processed.
The file system itself “packages” the information, so no extra overhead occurs. Once verified that the information is successfully written to the disk, byte level replication sends a copy of the I/O directly to the TCP/IP presentation layer, so no extra disk I/O. The “payload” only contains the information that has actually changed, not a 4k block regardless of what changed in that block.
This process is nearly immediate and has a low impact on the network so, it may not be necessary to establish a completely different network path for replication, and even if it is decided to do so, that network can be much more ‘optimized’ for use. Once the initial mirror is complete, only changed data is sent. If there is a network outage that is significant enough to impact replication, a difference mirror can be performed so only differences between source and target are sent, resulting in a faster “re-synch” time, all while still sending changed data to the destination.
Limitations of block level and byte level replication
Like many IT Tools, there are pros and cons to each one. Here are a few of the challenges and limitations for each of the technologies.
Block level replication tools often have limited ability to perform simultaneous activities, especially when performing migrations across infrastructure or cloud providers. For migrations, many of the available tools require a consolidation or replication server, or both. These are bottlenecks and areas of single points of failure that limit the ability to perform multiple simultaneous block level migrations without driving costs up for each consolidation and replication server.
Granular replication using block level tools is practically non-existent. Many are capable of excluding files and folders from the “image”, but you still have to contend with temporary cache files that get flushed to disk.
When using block level replication, a ‘conversion’ of the data may be required, and there can only be 1 destination. No ability to easily ‘split’ the data into multiple destinations (think merger and acquisitions).
When deploying for High Availability/Disaster Recovery (HA/DR), the last PIT is your recovery point which may be hours old. DR SLAs are usually long enough to failover a block level solution, but recovery won’t actually “start” until the variable cutover duration is completed.
Byte level replication is 100% agent based, which requires installation on both source and destination servers. The destination server must be active and running with the same base level OS (in most cases).
When deploying byte level replication, the users must actively manage and monitor the source and target as well as the replication status. IT Operations has extra overhead for each server it is deployed on.
- Only works with Local File Systems like NTFS, ReFs, EXTn, BtrFS and XFS. Does not support RAC/ASM, VxFS, SMB, NFS, CIFS or any other remote file system.
- Limited to Windows and Linux (RHEL, OEL, CentOS, Rocky, CloudLinux, SUSE, Ubuntu, Debian).
- ‘Special Handling’ for Microsoft Cluster Services and SQL clusters and no support for Linux Clusters.
Multiple Changes to the same information results in multiple I/Os being sent to the target. Byte level replication queues all the I/O until an acknowledgement from the destination server is provided before it is cleared from the queue. The amount of data is seldom an issue as long as the acknowledgement is received in a timely manner. If delays in response, memory queue rolls over to a disk queue. If the disk queue size is exceeded, the product stops replication.
Capabilities for block level and byte level replication
Again, like many IT Tools, there are pros and cons to each one. Here I describe a few of the capabilities for each of the technologies.
Block Level replication tools are often ‘fire and forget’. Once configured, they tend to continue working with little additional management.
- A block level solution can be found on nearly any storage type, file system and Operating System.
- Optimal DR for low activity or long RPO/RTO systems
- Could add value to a Malware recovery solution
- A big benefit for Block Level replication is when repeated changes to the same block of data occurs. Block level replication only sends the last change at the point the CBT Collection occurs. All changes to the same block are not Queued then sent.
Byte Level can take advantage of some of the hypervisors or cloud features, providing a lower cost solution for critical DR that has a very low RTO (about 15 min) and requires a crash-consistent RPO for rapid recovery after failure event.
- The destination infrastructure and hardware do not need to be the same. Right Size your servers on a different infrastructure and into a new disk size or type.
- Deploy target “snapshots” in HA/DR to provide an optional cutover point-in-time or to live data.
- Byte level replication can provide a granular replication set that automatically excludes system temporary cache files and other items that get deleted and recreated at reboot.
- Whether full server or files and folders, byte level replication allows for multiple destinations. Combine that with the inclusions and omissions lists, you can easily split or combine servers across multiple destinations (and Domains or Tenants) to help with any consolidation or distribution of data.
Which one is best for you to use?
So, with all that information it looks like this article is leaning on Byte Level replication. The answer may surprise you though.
Block Level is best for:
Block level replication is best used in local storage migrations on “like-for-like” technologies, Remote File Systems (CIFS, NFS, SMB) or Block-Blob/S3 “type” storage solutions where the ‘local’ file systems do not run.
For large storage arrays the bulk-copy capabilities of block level replication is often a better option, especially if the infrastructure is already in place. Archive, Static or Low Change data are also good candidates for block level replication.
Byte Level is best for:
Byte level replication is best used for “Lift-and-Shift” migrations and critical server availability where recovery times must be less than 15 minutes and recovery points must be at the point of failure.
Byte level replication is a Point-to-Point solution that has no limitations for parallel simultaneous use. There are no consolidation or replication servers between the source and destination in a “Lift-and-Shift” or an HA/DR deployment.
Additionally, the flexibility of byte level replication with support for inclusion/omission of selected files and folders, distribution or consolidation of data, critical-path recovery through point-in-time snapshots (fail over to live data or snapshot) no Impact DR testing and more makes byte level replication a must have in any ITOM and Services organizations.
Having multiple tools in your toolbox
When running an IT Operations Management organization, having multiple tools in your toolbox is an absolute must. Storage solutions will always be something that ITOM has to manage and, in doing so, block level replication tools will be an absolute go-to tool. However, ITOM will have to participate in unique and critical projects that require additional flexibility in a solution.
Having a byte level replication tool like OpenText Availability, Migrate and SQL Modernization will allow the IT team to tackle critical data movement projects with ease. Upgrading SQL, splitting a server across multiple destinations, and moving thousands of servers into a new infrastructure are all solid options for byte level replication.
Pushing terabytes of archive or low change data into a new storage array, providing DR for hundreds or thousands of servers and all the other things storage related for ITOM requires the bulk movement abilities of block level replication.
In conclusion, there is a solid need for both block and byte level replication but use them for the right challenges in the best way. Sure, you may need to purchase a license for byte level replication, but you can accomplish the Lift-and-Shift of more servers in less time, so the cost pays for itself in resource reduction, risk avoidance and project durations.
I would estimate that about 85 to 90% of your ‘estate’ does not require an RTO of 15 min and an RPO of near zero, so, deploy your block level recovery solution there, and focus the byte level on the remaining 10 to 15% of your HA and DR requirements.
A few more thoughts to consider:
If your business environment:
- Can take an outage to move the system and data
- Is not changing Block, Sector or Storage sizes, the number or type of CPU
- Utilizes high bandwidth and low latency networks
- Only has one destination per source
- Does not have any disk volumes greater than 8tb
- Utilizes NFS, CIFS/SMB file system protocols
- Does not utilize mixed protocols like iSCSI, FC, InfiniBand or multipath IO functions
Then you may see a benefit with block based replication.
If your business environment:
- Has low RPO or RTO requirements
- Has a need to 'right-size' the destination
- Looking to move off BIOS system and into UEFI or Gen2 type VMs
- Functions over a low bandwidth or high latency network
- Include Server consolidation or distribution
- Looking to 'modernize' or optimize Microsoft SQL License and versions
- Have disk sizes greater than 8TB
- Have a very high rate of change
- Includes Microsoft Cluster Services or SQL Clusters that need to 'Lift-and-Shift' to a new location
- Has flexible and varied infrastructure to support
- Moving to or recovering into a 'unique' infrastructure
Then you may want to utilize byte level replication

