
- Home
- Community overview
- Webroot
- Got a Question?
- Users unable to login to terminal server with Webroot installed.
Users unable to login to terminal server with Webroot installed.
- February 22, 2016
- 198 replies
- 2059 views

- Fresh Face
We are deploying Webroot to our clients and have been running into an issue with users unable to login at a certain point. After testing we found it has to do with Webroot being installed on there but we cant figure out what is causing the issue and we've had to remove Webroot. This seems to only be affecting Server 2008 R2 environments.
198 replies
") +26
+26- Manager, Channel Sales
- November 3, 2016
Understand everyones frustration. The point wasn't that that KB will fix anything other than what it states, but that MS is as culpable in their core codes stack, regardless of version. Windows 2008 RDS is a precursor to 2012 and I'd bet there's similar code in both. The user experience is not the point (blue screen, black screen, spinning icons), rather the error is related to 'deadlocks', the common denminator. Several code additions put into our agent at various releases was an attempt to stop the deadlocks (all in our release notes). Obviously there's still an issue at the virtualization stack and MS code that needs to be addressed along with what ever is in our "kernel" code that's affecting that defect that's been well documented.
That was my point, not that the KB is the magic fix, but that the core problem is still with the MS stack on virtualized resources that's been well documented.
Our developers are looking into many variables, not just one specific area, but what ever it is, it's causing the deadlock which simply reports to event logs as Winlogon 4005. It could be something else and all variables are being considered, but the obvious is the OS stack.
That was my point, not that the KB is the magic fix, but that the core problem is still with the MS stack on virtualized resources that's been well documented.
Our developers are looking into many variables, not just one specific area, but what ever it is, it's causing the deadlock which simply reports to event logs as Winlogon 4005. It could be something else and all variables are being considered, but the obvious is the OS stack.
Shane Cooper | Manager, Channels Sales (RMM & Strategic Partners)


- New Voice
- November 3, 2016
I look forward to further updates as this progresses.
Crossy
- November 3, 2016
Good morning
Had the issue again yesterday during the day.
Those who terminated their RDP connection were unable to get back in.
We performed a Turn off in the evening and tested connection with success afterwards but received 5:00 am phone call from staff advising access had once again gone throughout the evening.
The server overnight would of not had any RDP connections and would of been only performing mainteneance and admin tasks overnight.
Our plan is to remove Webroot from the Terminal Server and install a replacement AV. We may use a 30 day trial, and hope that issue is resolved in that period. We also require to adhere with PCI DSS compliance, so this opens a can of worms for us.
Will keep you updated if, the removal of Webroot is a success.
Hoping for a speedy resolution.
- New Voice
- November 3, 2016
Just to clarify that I have a mixture of Server 2008R2 and Server 2012R2 that are all physical and all experience the same issue. The MS Patches mentioned are not installed on any of the servers. Removing Webroot resolves the issue, I have not had a single re-occurence of the issue on any of my servers after removing Webroot from them.
- November 3, 2016
My concern is that this problem is bigger than just RDS servers, but obviously RDS issues grab the spotlight due to their direct impact on the end user. Please read the entire post before dismissing what I am about to say.
In the month or so that we have been using Webroot we have been tracking the cause of intermittent application and scripting hangs across all of our tenants. This is happening on both clients and servers - both physical and virtual. This first caught our attention with some of the maintenance scripts we use. Just a few examples:
1) powershell.exe may be called to run a simple one line get-command and pipe the output to a text file. Powershell will execute, the output file will be opened, but the process will halt.
2) Similarly, cmd.exe gets called to run a simple one-line DOS command and output to a text file. The command will execute, the output file will be created, but the process will halt.
3) Random processes used by our Managed Services platform, such as patch management and scripting, will either hang or fail mid-way through execution.
What we've observed is that the processes are often being blocked by *something* and cannot be killed by any means (Task Manager, Taskill, Powershell Kill, etc) In most cases a reboot will be necessary to release the process, and then subsequent executions of the same script/task/process will work as expected. Just to reiterate - intermittently across ALL tenants, all OSs and environments, and nothing other than a reboot is needed to get everything working again.
As we started to focus on the cause of background scripts/tasks/processes intermittently failing, we also noticed a huge spike in random LOB application process hangs. Similar to above, processes that spawn, halt and cannot be killed, or that just abnormally abort.
Taking this into consideration, my opinion is that the "RDS deadlock" is just a symptom of a much bigger problem. Consider what would happen if Webroot was interacting with authentication and/or RDS related processes in the same way we suspect it is interacting with other processes. It's not inconceivable that the problems are related.
I understand that this post will not go over well and will likely be dismissed. But if I am wrong, then how do we explain that these symptoms seem to appear with the installation of Webroot and go away with the removal of Webroot? Also, If this is not a Webroot issue, then why does Webroot Support recommend rolling back to an old version of the program that does not (as far as we know) have this problem?
So I am clear on my intent, I am not trying to bash Webroot in any way. We have an investment in this solution, and we are all on the same team here. I am simply trying to get someone to consider that the RDS problem *could* just be a symptom, and that focusing on it exclusively may not get us closer to resolution.
I appreciate the ongoing effort by Webroot Support to work through this issue, and that they are keeping us in the loop as much as possible.
In the month or so that we have been using Webroot we have been tracking the cause of intermittent application and scripting hangs across all of our tenants. This is happening on both clients and servers - both physical and virtual. This first caught our attention with some of the maintenance scripts we use. Just a few examples:
1) powershell.exe may be called to run a simple one line get-command and pipe the output to a text file. Powershell will execute, the output file will be opened, but the process will halt.
2) Similarly, cmd.exe gets called to run a simple one-line DOS command and output to a text file. The command will execute, the output file will be created, but the process will halt.
3) Random processes used by our Managed Services platform, such as patch management and scripting, will either hang or fail mid-way through execution.
What we've observed is that the processes are often being blocked by *something* and cannot be killed by any means (Task Manager, Taskill, Powershell Kill, etc) In most cases a reboot will be necessary to release the process, and then subsequent executions of the same script/task/process will work as expected. Just to reiterate - intermittently across ALL tenants, all OSs and environments, and nothing other than a reboot is needed to get everything working again.
As we started to focus on the cause of background scripts/tasks/processes intermittently failing, we also noticed a huge spike in random LOB application process hangs. Similar to above, processes that spawn, halt and cannot be killed, or that just abnormally abort.
Taking this into consideration, my opinion is that the "RDS deadlock" is just a symptom of a much bigger problem. Consider what would happen if Webroot was interacting with authentication and/or RDS related processes in the same way we suspect it is interacting with other processes. It's not inconceivable that the problems are related.
I understand that this post will not go over well and will likely be dismissed. But if I am wrong, then how do we explain that these symptoms seem to appear with the installation of Webroot and go away with the removal of Webroot? Also, If this is not a Webroot issue, then why does Webroot Support recommend rolling back to an old version of the program that does not (as far as we know) have this problem?
So I am clear on my intent, I am not trying to bash Webroot in any way. We have an investment in this solution, and we are all on the same team here. I am simply trying to get someone to consider that the RDS problem *could* just be a symptom, and that focusing on it exclusively may not get us closer to resolution.
I appreciate the ongoing effort by Webroot Support to work through this issue, and that they are keeping us in the loop as much as possible.
+26- Manager, Channel Sales
- November 3, 2016
I read the post thouroughly. I believe these are different and unrelated issues that can be addressed seperately.
Just so everyone understands, our technology touches a lot of different areas and layers on an endpoint. We are not an AV scanning product only. We have different "shields" that monitor and watch different attack vectors, so often times the issues that appear related are not even close to be related. Also our technology is very different than any other traditional AV on the market, so comparing is irrelevant.
Our agent is a kernel level code base that operates below the OS layer. The TS error/issue is happening at this layer/level, not at the application/memory/ etc... layer. Deadlocks are an issue at the kernel, where we have to run custom debug software to capture logs.
The performance concern you mentioned appears at the OS layer where our agent many be monitoring action taken at that layer that may appear malicious. There are several options to try and ascertain what's happening with regards to a process being monitored. (Identity protection is often a culprit and the monitored process is reported in the Identity Protection screen on an endpoint under Application Protection, not in any log file, unfortunately. Find that directory where the process is firing and see if it's set to Protect-allow-deny) If it's not set to Allow, then whitelist the dir it's running.) This is a common situation with speicalty products, like CC drivers or custom plug-ins etc.
Whitelisting - if it's not showing up there, then locate the log file in Program DataWRDATA and find the monitored process. It could be a core monitor that just needs whitelisting. If it's a commercial product, open a ticket and have our support push it up to AMR for rules based whitelisting.
Scanning - we view scanning as legacy requirement and only one area of detection (small variable) and while not mentioned here on this thread it comes up all the time. To clarify, we scan below the OS layer as well by looking at the MBR records and scan files at the byte level. So, given how RDS works, there could be areas to address/review there. So, just to be clear dev is looking at many areas and levels regarding the TS issue, not just one.
scooper@webroot.com - 720-842-3562 (I'm located at our corporate offices in Colorado.)
Thanks - Shane
- November 5, 2016
Glad I found this thread. I can't tell you how many hours we've lost on this, also an MS case, and frustrated customers.
Being relativly new to Webroot, could somebody let me know where we could find a version 8 installer for us to roll back Webroot on affected systems?
Being relativly new to Webroot, could somebody let me know where we could find a version 8 installer for us to roll back Webroot on affected systems?
+26- Manager, Channel Sales
- November 5, 2016
http://download.webroot.com/8.0.8.53/wsasme.exe
Fully uninstall older version and remember, whitelisted folders will not work with this version.
Hope this helps.
Shane Cooper | Manager, Channels Sales (RMM & Strategic Partners)
- November 6, 2016
Shane,
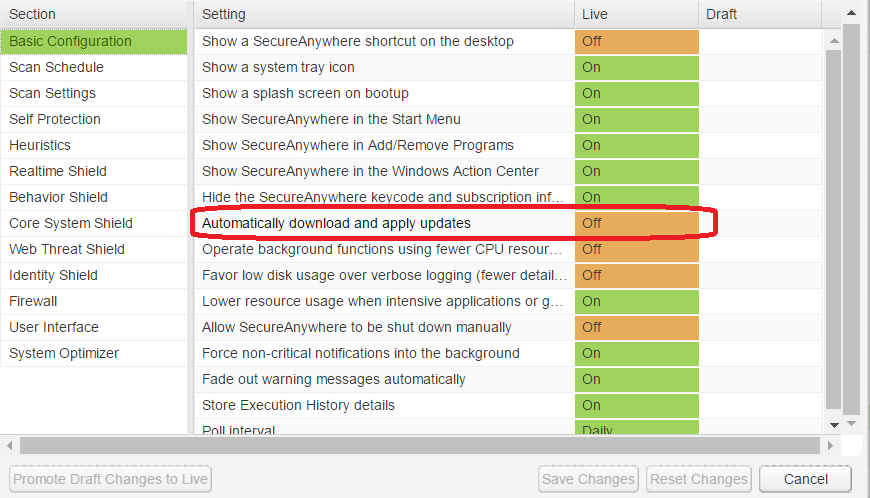
Removed V9. Downloading V8 and insatlling it, it immediatly downloads an update and self-updates to V9. How can I stop that?
Removed V9. Downloading V8 and insatlling it, it immediatly downloads an update and self-updates to V9. How can I stop that?
+26- Manager, Channel Sales
- November 6, 2016
Policy setting in basic configuration. Turn off automatic updates.
- November 6, 2016
I just wanted to post some details about our enviroment in case it will help.
All of our environments are running Hyper-V. Most of our clients connect directly to a terminal server and have the Remote Desktop Gateway directly on the terminal server.
We also have a couple clients who have a separate VM for the RDS Gateway service because they have load balanced terminal servers. These clients are NOT having the issue.
Our environment consists of the following:
Physical Servers: Dell R630's in a Hyper-V Cluster environment.
OS: Windows 2012 R2 Datacentre
Physical NIC’s: 2 x QLogic BCM57800 in a Bond for Hyper-V using Microsoft Network Adapter Multiplexor Driver. The VM's themselves have VLANs assigned to them.
The servers host multiple customer enviroments.
I have looked at the configuration on 3 customers running on these hosts an found the following:
Customer 1 – Hosted on the servers listed above:
2012 R2 TS VM (clients connecting directly to the TS via RDS Gateway running directly on the terminal server.
Lots of 4005 errors in the application log
Lots of complaints from users lately
Customer 2 – Hosted on the servers listed above::
2012 R2 TS VM (clients connecting directly to the TS via RDS Gateway running directly on the terminal server.
Lots of 4005 errors in the application log
This client uses the TS all of the time as they don’t have desktops. They would have complained if there was a problem.
Customer 3 – Hosted on the servers listed above::
1 x Front End RDS Gateway Server (2012 R2)
2 x Back-End Terminal Servers (2012 R2)
There are no 4005 errors on this server.
Client runs 24x7 and has about 50 users connecting. We would have heard if this was a problem.
Customer 4 – Not running on the same hardware as #1-3
Onsite Dell T420 Running Hyper-V on Windows 2012 R2 Datacentre
TS VM (clients connecting directly to the TS via RDS Gateway running directly on the terminal server.
Lots of 4005 errors in the application log
Lots of complaints from users lately
Broadcom Nic's on host
Please let me know if there's any information I can provide from our enviroments that would be useful.
Jason
All of our environments are running Hyper-V. Most of our clients connect directly to a terminal server and have the Remote Desktop Gateway directly on the terminal server.
We also have a couple clients who have a separate VM for the RDS Gateway service because they have load balanced terminal servers. These clients are NOT having the issue.
Our environment consists of the following:
Physical Servers: Dell R630's in a Hyper-V Cluster environment.
OS: Windows 2012 R2 Datacentre
Physical NIC’s: 2 x QLogic BCM57800 in a Bond for Hyper-V using Microsoft Network Adapter Multiplexor Driver. The VM's themselves have VLANs assigned to them.
The servers host multiple customer enviroments.
I have looked at the configuration on 3 customers running on these hosts an found the following:
Customer 1 – Hosted on the servers listed above:
2012 R2 TS VM (clients connecting directly to the TS via RDS Gateway running directly on the terminal server.
Lots of 4005 errors in the application log
Lots of complaints from users lately
Customer 2 – Hosted on the servers listed above::
2012 R2 TS VM (clients connecting directly to the TS via RDS Gateway running directly on the terminal server.
Lots of 4005 errors in the application log
This client uses the TS all of the time as they don’t have desktops. They would have complained if there was a problem.
Customer 3 – Hosted on the servers listed above::
1 x Front End RDS Gateway Server (2012 R2)
2 x Back-End Terminal Servers (2012 R2)
There are no 4005 errors on this server.
Client runs 24x7 and has about 50 users connecting. We would have heard if this was a problem.
Customer 4 – Not running on the same hardware as #1-3
Onsite Dell T420 Running Hyper-V on Windows 2012 R2 Datacentre
TS VM (clients connecting directly to the TS via RDS Gateway running directly on the terminal server.
Lots of 4005 errors in the application log
Lots of complaints from users lately
Broadcom Nic's on host
Please let me know if there's any information I can provide from our enviroments that would be useful.
Jason
- November 7, 2016
Hi All,
We've got Webroot running on many 10's of servers and the issue doesn't present on all of them. So I thougtt I'd share my findings so we can narrow things down.
1 - Servers that have presented with the "I can't log in" issue only twice, have many many 4005's in the event logs. So a 4005 does seem to be realted but doesn't necessarily happen once users can't log in
2 - We've had no complains from smaller sites. Our data shows zero calls from sites with only a few users. No magic 'line in the sand' number here - but maybe, there's something in this. If I had a gut feel, I'd think that it might be a 'number of logon events' thing. So maybe sites with users that log in and stay in are less likely to get it than sites with people who frequentloy log on and off.
This might also explain why some here who are doing 24 hour reboots are getting mixed results? If doing the reboot means you fly below the magic number of logons, then you migth be okay.
3 - For us, all HyperV systems (one 2008r2 HyperV, the rest 2012r2 HyperV) and 2008r2 and 2012r2 terminal servers. All Dell hardware, but we're a Dell shop.
4 - Can somebody confirm the status of the various patches mentioned throughout this thread? Is the suitation that you SHOULD have KB3179574 installed for 12r2 and NOT have the two 08r2 patches?
Not filled with a lot of confidence knowing this has existed since April. Unrelated but we also copped a heap of blue screens due to some clash with WR's keylogger and MS keyboards, another product we sell a lot of. I just can't work out why so many of my peers have 1000's of installs without issue?
We've got Webroot running on many 10's of servers and the issue doesn't present on all of them. So I thougtt I'd share my findings so we can narrow things down.
1 - Servers that have presented with the "I can't log in" issue only twice, have many many 4005's in the event logs. So a 4005 does seem to be realted but doesn't necessarily happen once users can't log in
2 - We've had no complains from smaller sites. Our data shows zero calls from sites with only a few users. No magic 'line in the sand' number here - but maybe, there's something in this. If I had a gut feel, I'd think that it might be a 'number of logon events' thing. So maybe sites with users that log in and stay in are less likely to get it than sites with people who frequentloy log on and off.
This might also explain why some here who are doing 24 hour reboots are getting mixed results? If doing the reboot means you fly below the magic number of logons, then you migth be okay.
3 - For us, all HyperV systems (one 2008r2 HyperV, the rest 2012r2 HyperV) and 2008r2 and 2012r2 terminal servers. All Dell hardware, but we're a Dell shop.
4 - Can somebody confirm the status of the various patches mentioned throughout this thread? Is the suitation that you SHOULD have KB3179574 installed for 12r2 and NOT have the two 08r2 patches?
Not filled with a lot of confidence knowing this has existed since April. Unrelated but we also copped a heap of blue screens due to some clash with WR's keylogger and MS keyboards, another product we sell a lot of. I just can't work out why so many of my peers have 1000's of installs without issue?
- New Voice
- November 7, 2016
So I thought this issue was fixed for those of us hosting our 2008R2 RDS servers on ESX hosts - it is not, the same old behavior is back, 4005 errors and unable to login new users while existing sessions are unaffected. Rebooting nightly isn't enough anymore as they are preventing logins randomly in the middle of the day necessitating reboots. So I hope devs are not only looking at hyperv hosted servers now.
Another thing that was mentioned a lot in the past but I don't see recently mentioned, it was previously thought that this issue was related to having very high PID numbers on the system, was this for sure eliminated as related? It would correlate with why this issue doesn't seem to occur on lightly used RDS servers but is very common on busy ones (20+ concurrent sessions).
Another thing that was mentioned a lot in the past but I don't see recently mentioned, it was previously thought that this issue was related to having very high PID numbers on the system, was this for sure eliminated as related? It would correlate with why this issue doesn't seem to occur on lightly used RDS servers but is very common on busy ones (20+ concurrent sessions).
+26- Manager, Channel Sales
- November 7, 2016
All environments are being tested and reviewed, including non-virtual systems. HTH
Shane Cooper | Manager, Channels Sales (RMM & Strategic Partners)
- New Voice
- November 7, 2016
Is this issue being worked on? Is there a fix?
We're experiencing the same behaviour on a Server 2012 R2 RDS server.
Black screens when loggin in and once a week (sometimes more) no logons are even possible.
Resolution: reboot machine.
We're experiencing the same behaviour on a Server 2012 R2 RDS server.
Black screens when loggin in and once a week (sometimes more) no logons are even possible.
Resolution: reboot machine.

- Popular Voice
- November 7, 2016
The issue discussed here is really with RDS servers running on Server 2008R2.
There is a separate (Microsoft) issue with Server 2012R2 that exhibits the behaviors you're seeing, i.e. black screen when users try to login. Here's a TechNet thread that discusses this at length:
https://social.technet.microsoft.com/Forums/windowsserver/en-US/4052abbc-e98c-4a94-9255-ae92deb686d2/event-4005-winlogin-windows-logon-process-has-unexpectedly-terminated?forum=winserverTS
Latest from Microsoft is that this is a known issue and they are working on a fix (hopefully to be released in the November rollup). There are also some potential workarounds listed in that thread that may work for you.
Hope that helps.
- New Voice
- November 7, 2016
Having a problem trying to install the previous version, even with the policy created and applied to this specific agent. Mind taking a look and telling me what I'm doing wrong?
- New Voice
- November 7, 2016
Try installing it with the /noupd parameter. It is likely updating before the policy was downloaded.
See page2 in this thread for an example.
See page2 in this thread for an example.
- November 8, 2016
Joining this discussion as well; hopefully we're going to see some action soon... -
17 RDP servers that I'm now having to restart... Usually very early in the morning. PRTG and other such remote monitoring tools dont seem to notice the service has locked up so I'm hearing this from actual pissed off users wanting to do work.
I've removed Webroot from them all and will monitor for another week - absolutely not an ideal situation at all.
17 RDP servers that I'm now having to restart... Usually very early in the morning. PRTG and other such remote monitoring tools dont seem to notice the service has locked up so I'm hearing this from actual pissed off users wanting to do work.
I've removed Webroot from them all and will monitor for another week - absolutely not an ideal situation at all.
- November 8, 2016
I am so glad I found this thread. I am looking to change AV's and Webroot was in the hot seat. I've got 2000+ seats, however a huge number of RDS servers and this would probably lose me my job if I'd put this forward as the recommended replacement.
I respect that it's something that sits with Microsoft currently, however from what I understand it's only affecting Webroot users (meaning it's something with Webroot itself that is causing the fault). There must be something in the new connector causing it, as the old connector is fine apparently? Surely that means Webroot has some degree of control over mitigating the problem?
Really hoping you guys can get it sorted soon.
I respect that it's something that sits with Microsoft currently, however from what I understand it's only affecting Webroot users (meaning it's something with Webroot itself that is causing the fault). There must be something in the new connector causing it, as the old connector is fine apparently? Surely that means Webroot has some degree of control over mitigating the problem?
Really hoping you guys can get it sorted soon.
- November 8, 2016
Hey in a private forum I am part of, I've opened a can of worms saying "how is there so many users here with Webroot not expeiencing this issue". In come the "oh my god I have been bashing my head against a wall for ages" replies!
Anyway - one guy said that he runs WR without firewall and web shield components active and he has 10's of 08r2 RDS boxes without issue.
We did NOT have any issues when we ran Webroot in our initial install profile which we have as a 'look but dont touch' profile. So maybe there is some substance to this?
Maybe somebody who can't do without webroot, who has RDS boxes that can't make it through the day, could change their profiles to disable these two modules to see if it helps?
In the mean time, we have introduced 24 hour reboots for affected systems as most of ours can make it through 24 hours. If they can't, they are getting a V8 rollback.
Anyway - one guy said that he runs WR without firewall and web shield components active and he has 10's of 08r2 RDS boxes without issue.
We did NOT have any issues when we ran Webroot in our initial install profile which we have as a 'look but dont touch' profile. So maybe there is some substance to this?
Maybe somebody who can't do without webroot, who has RDS boxes that can't make it through the day, could change their profiles to disable these two modules to see if it helps?
In the mean time, we have introduced 24 hour reboots for affected systems as most of ours can make it through 24 hours. If they can't, they are getting a V8 rollback.
+26- Manager, Channel Sales
- November 8, 2016
All - I've been asked by WR Management to gather specific contact information. Please send me contact information (Name, Company, email and phone) privately via email so we can contact everyone directly as we work through this situation. While I intend to post on this forum, given the nature of the situation, Webroot feels compelled to contact anyone effected directly, personally.
Thanks,
Shane - scooper@webroot.com
Thanks,
Shane - scooper@webroot.com
Shane Cooper | Manager, Channels Sales (RMM & Strategic Partners)
- November 9, 2016
Hi all,
I had my first occurence of this (running it on a single RDS server for testing). Some information about the environment below:
OS - Server 2012 R2, fully patched.
P/V - Virtualised on VMware ESXi 6.0.0 249585 (HP Build)
Server - HP BL460c Gen 9 blade
Uptime - 2 days 4 hours
Time of lock up - 12.36pm
CPU - 4 cores
RAM - 8gb
NIC - VMXNET3
Running the latest version of Webroot on the Default Server Policy. No policy changes at all.
Symptoms included a bunch of 4005 errors in the log, and new session unable to logon. New sessions sat on "Preparing destination computer" in the RDS client. Existing sessions were fine. Unable to reboot cleanly through the hypervisor as it just sat there on "Restarting", had to force reset it
The RDS server services 4 people currently, but really only has 2 active at any time, so it's not a load problem. It's also a fairly new server - it doesn't have much installed and it really is a low touch VM.
If you need any more information, please let me know.
Joe
I had my first occurence of this (running it on a single RDS server for testing). Some information about the environment below:
OS - Server 2012 R2, fully patched.
P/V - Virtualised on VMware ESXi 6.0.0 249585 (HP Build)
Server - HP BL460c Gen 9 blade
Uptime - 2 days 4 hours
Time of lock up - 12.36pm
CPU - 4 cores
RAM - 8gb
NIC - VMXNET3
Running the latest version of Webroot on the Default Server Policy. No policy changes at all.
Symptoms included a bunch of 4005 errors in the log, and new session unable to logon. New sessions sat on "Preparing destination computer" in the RDS client. Existing sessions were fine. Unable to reboot cleanly through the hypervisor as it just sat there on "Restarting", had to force reset it
The RDS server services 4 people currently, but really only has 2 active at any time, so it's not a load problem. It's also a fairly new server - it doesn't have much installed and it really is a low touch VM.
If you need any more information, please let me know.
Joe
- Popular Voice
- November 10, 2016
Rather than uninstalling Webroot completely, I followed the advice here to just disable it (put the machine in the 'unmanaged' policy and shut down protection).
Webroot service stays running in this case.
Mistake.
Server locked up again today, same issues. Hard reboot, logged in, uninstalled Webroot completely.
I really hope that's the last of this.
Webroot service stays running in this case.
Mistake.
Server locked up again today, same issues. Hard reboot, logged in, uninstalled Webroot completely.
I really hope that's the last of this.
Login to the community
No account yet? Create an account
Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.
Scanning file for viruses.
Sorry, we're still checking this file's contents to make sure it's safe to download. Please try again in a few minutes.
OKThis file cannot be downloaded
Sorry, our virus scanner detected that this file isn't safe to download.
OK